VocabularyAnalyzer
A WebApp to produce distributions of keywords and parts of speech in a given PDF
Project maintained by fabriziomiano Hosted on GitHub Pages — Theme by mattgraham
Vocabulary analyzer
Are you always using the same words in your scientific papers? This is a tool to run a text analysis on PDF files containing an English corpus.
What is it?
It’s essentially the Flask WebApp of the repo VocabularyAnalyzer, a simple tool to extract keywords and Part-Of-Speech distributions from a given PDF.
How to run
Install Python3.6+, create a virtualenv and, within the environment,
pip install -r requirements.txt.
Then run
python runserver.py
If all’s good the local webapp will be up at http://127.0.0.1:5000, aka localhost.
Considerations
The tool is designed to run only on searchable PDF, namely PDF files in which the text can be selected and copied. That’s it!
Results
Here there are the sample results obtained by running on a PDF of some proceedings I wrote a long time ago, taken from here.
Word cloud

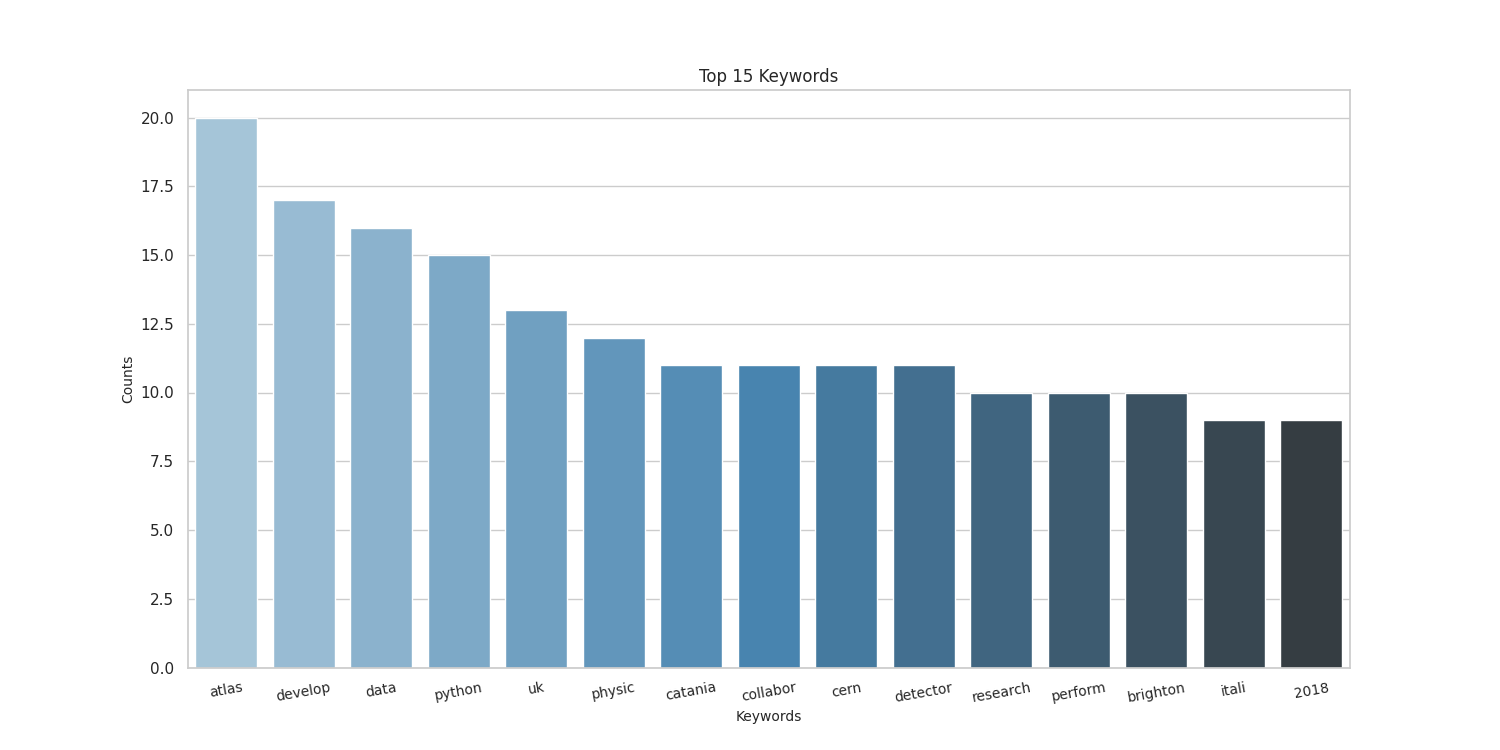
Top 20 keywords
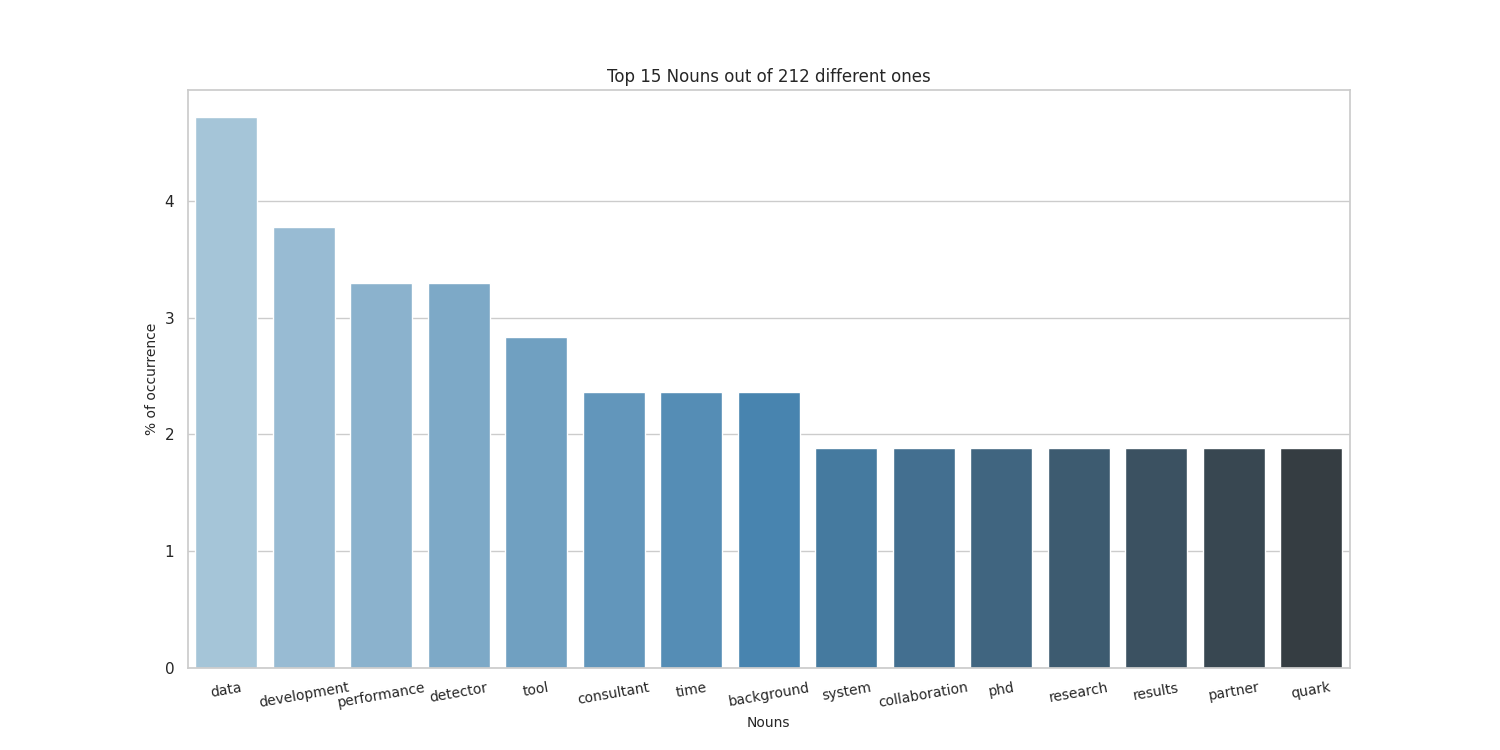
Top 20 nouns
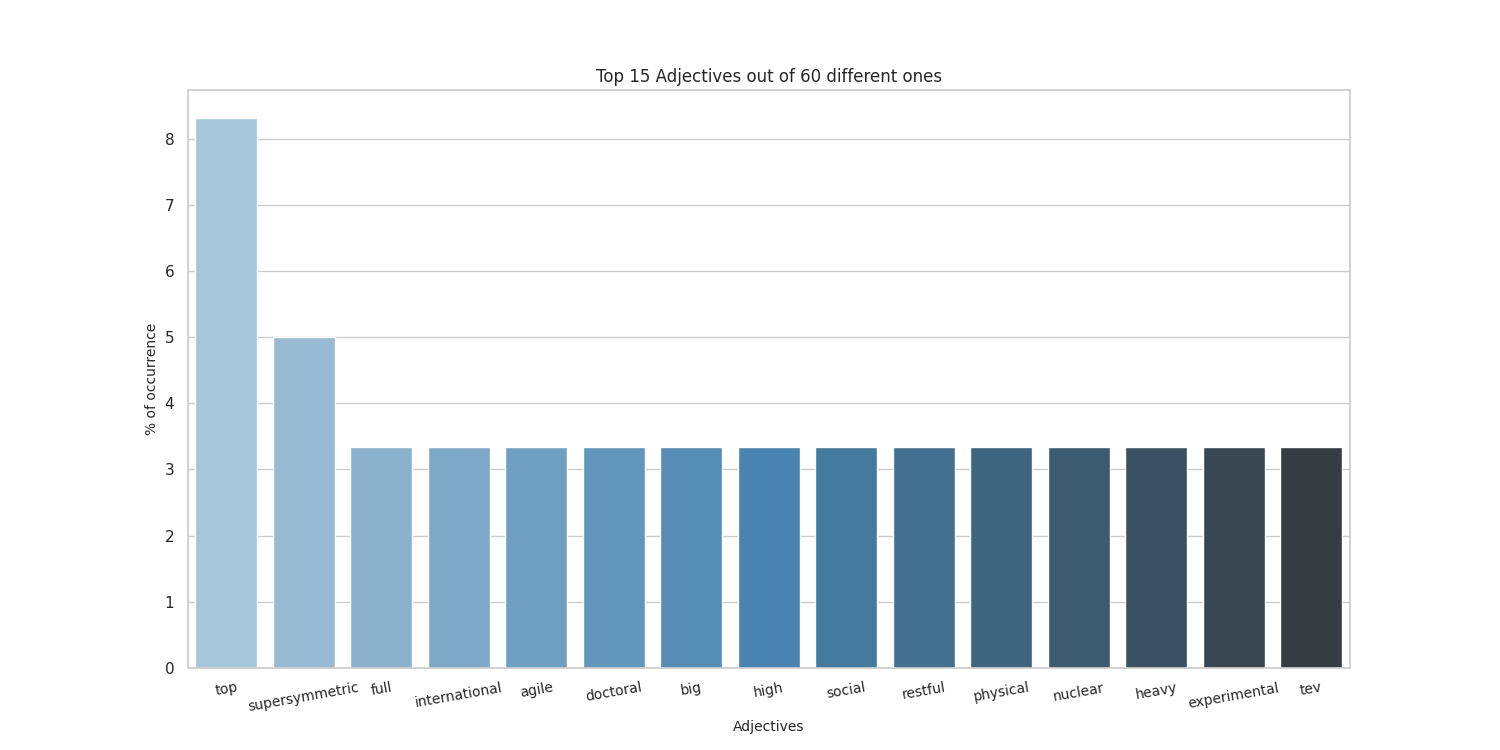
Top 20 adjectives
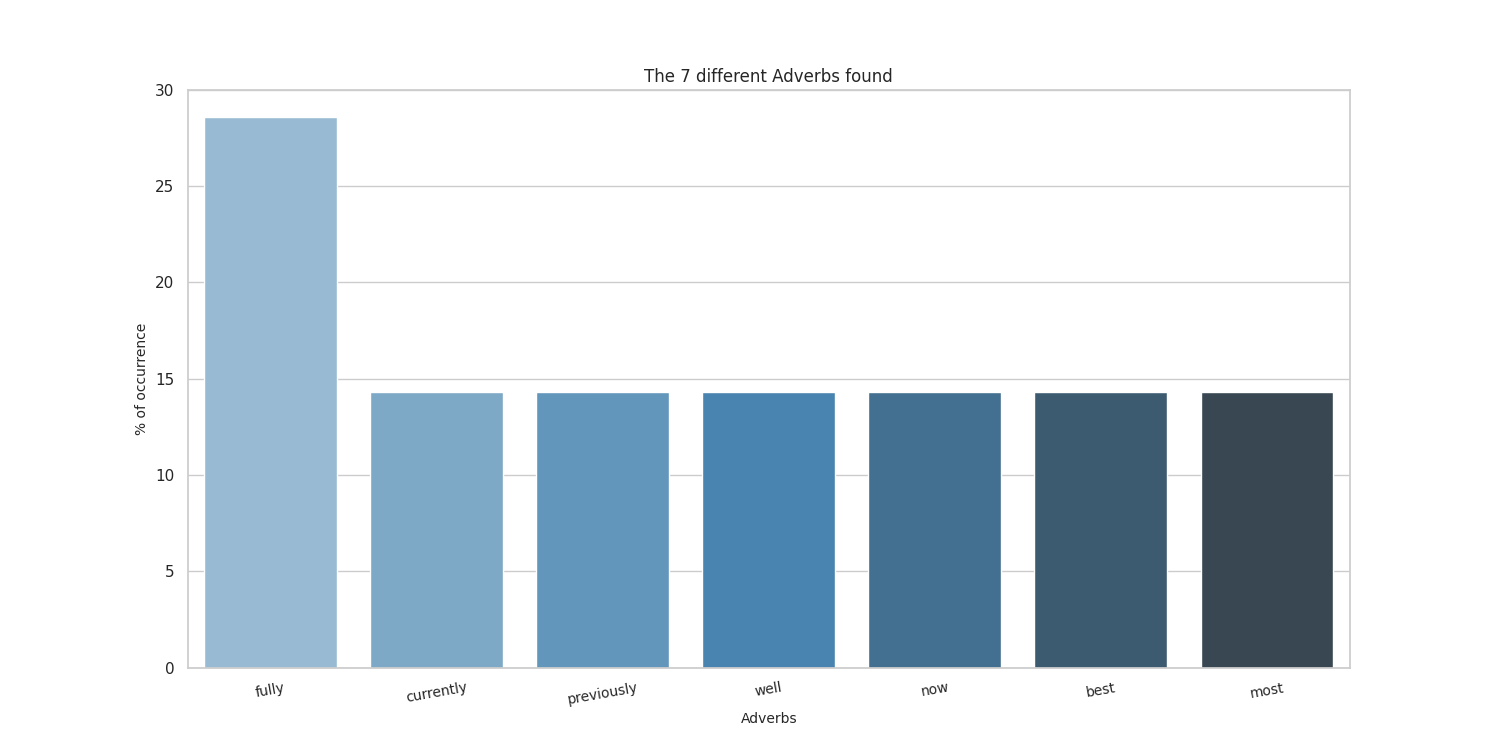
Top 20 adverbs
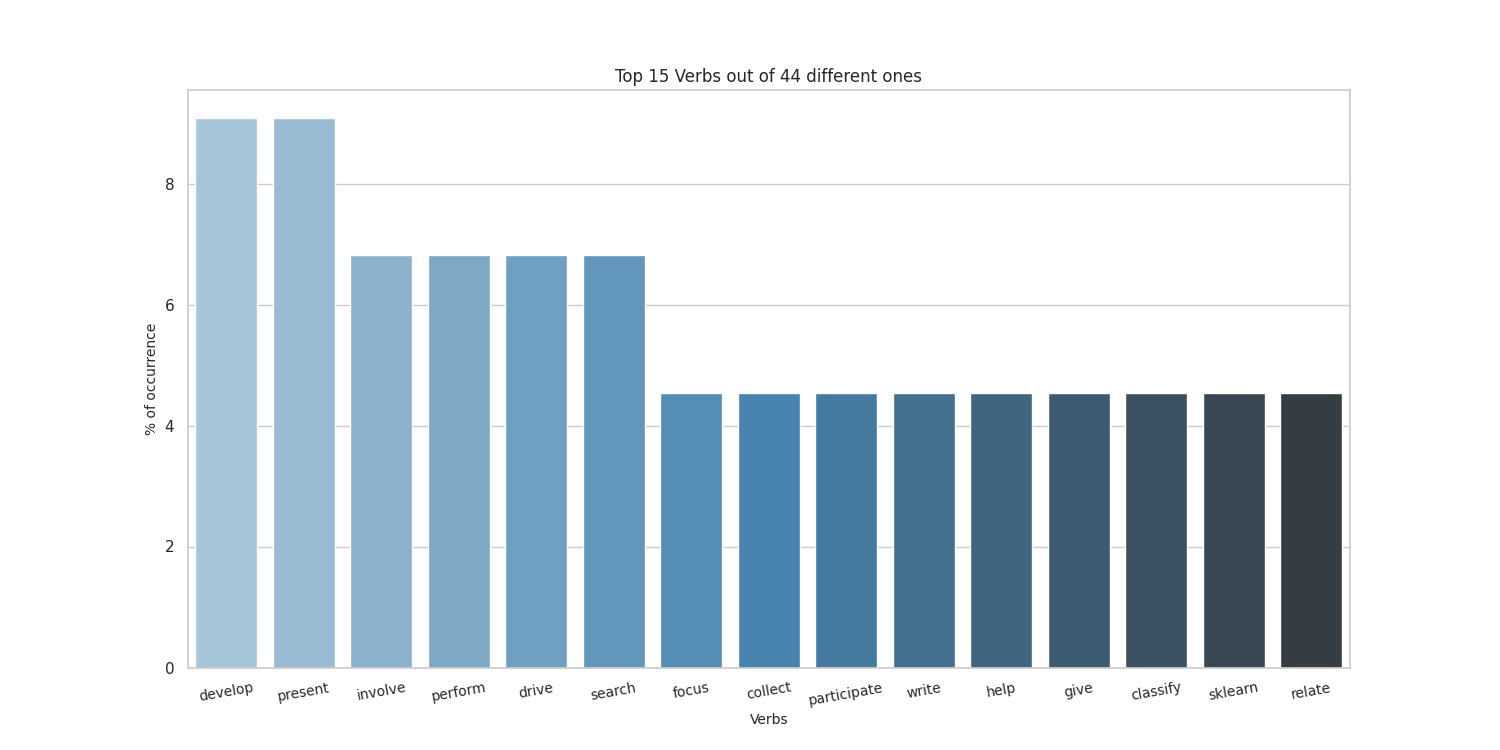
Top 20 verbs
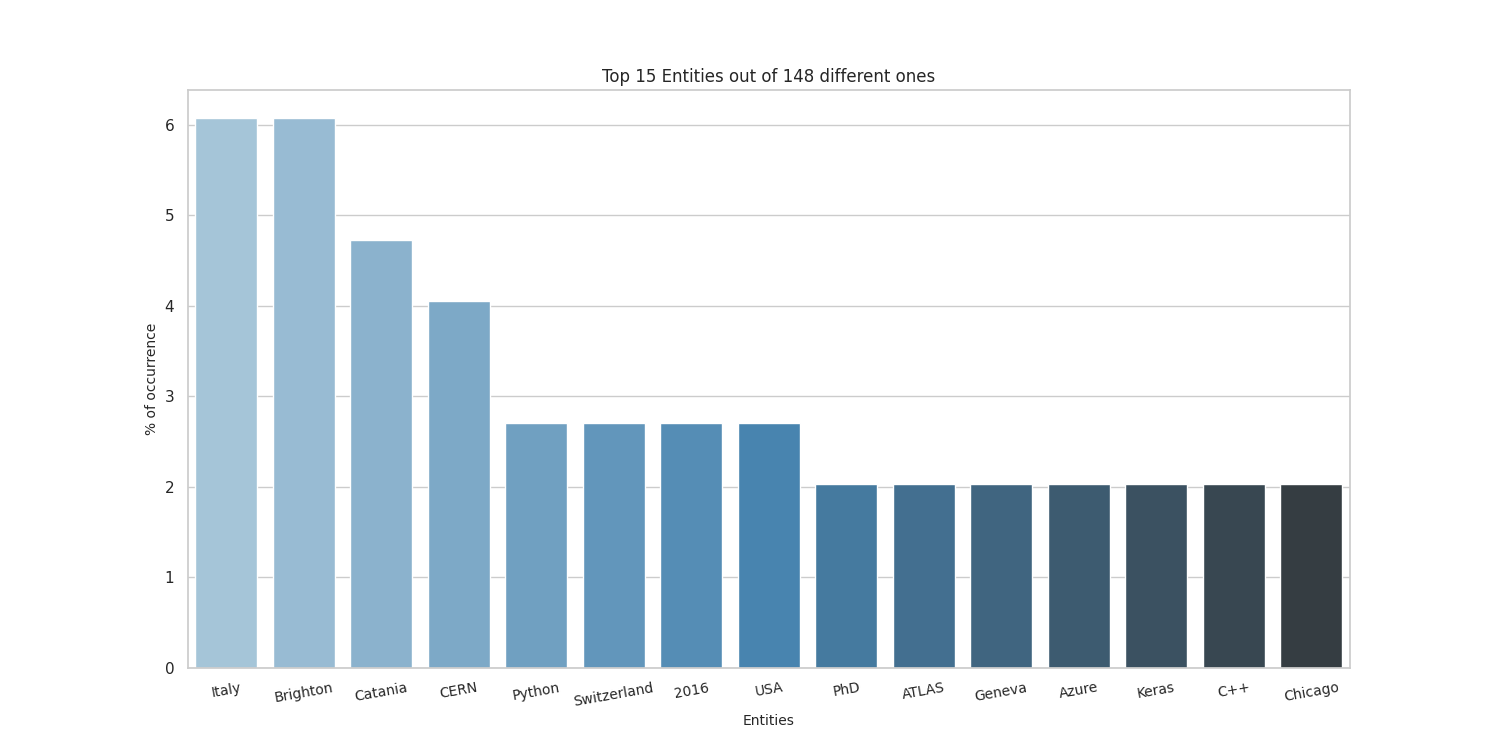
Top 20 entities
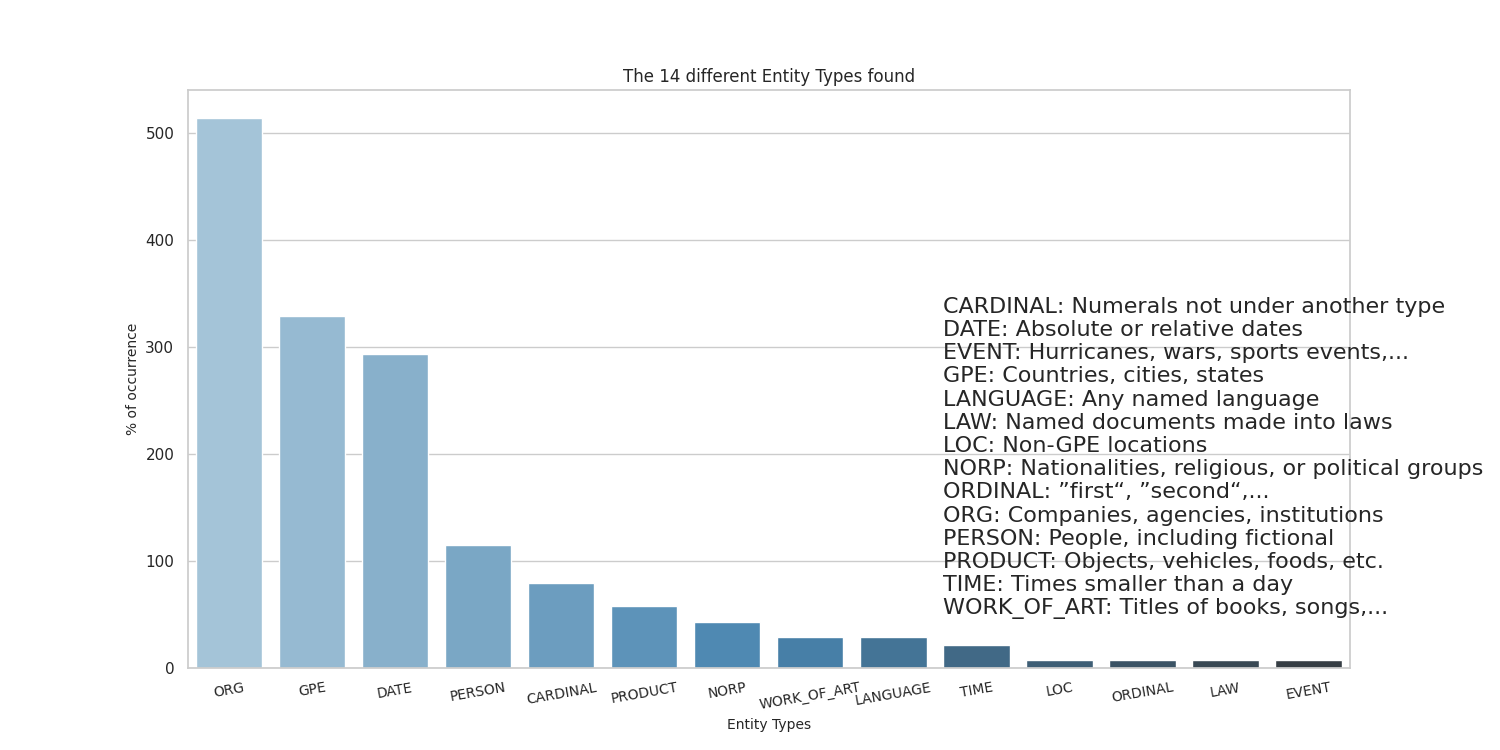
Top 20 entity types
Acknowledgements
Thanks to the people at spaCy for the NE part, and to the guys who made word cloud for the awesome word-cloud images that can be produced.